Molly Daniel, Annie Karitonze, Karenna Kung, Emma Ruckle, Caroline Zouloumian
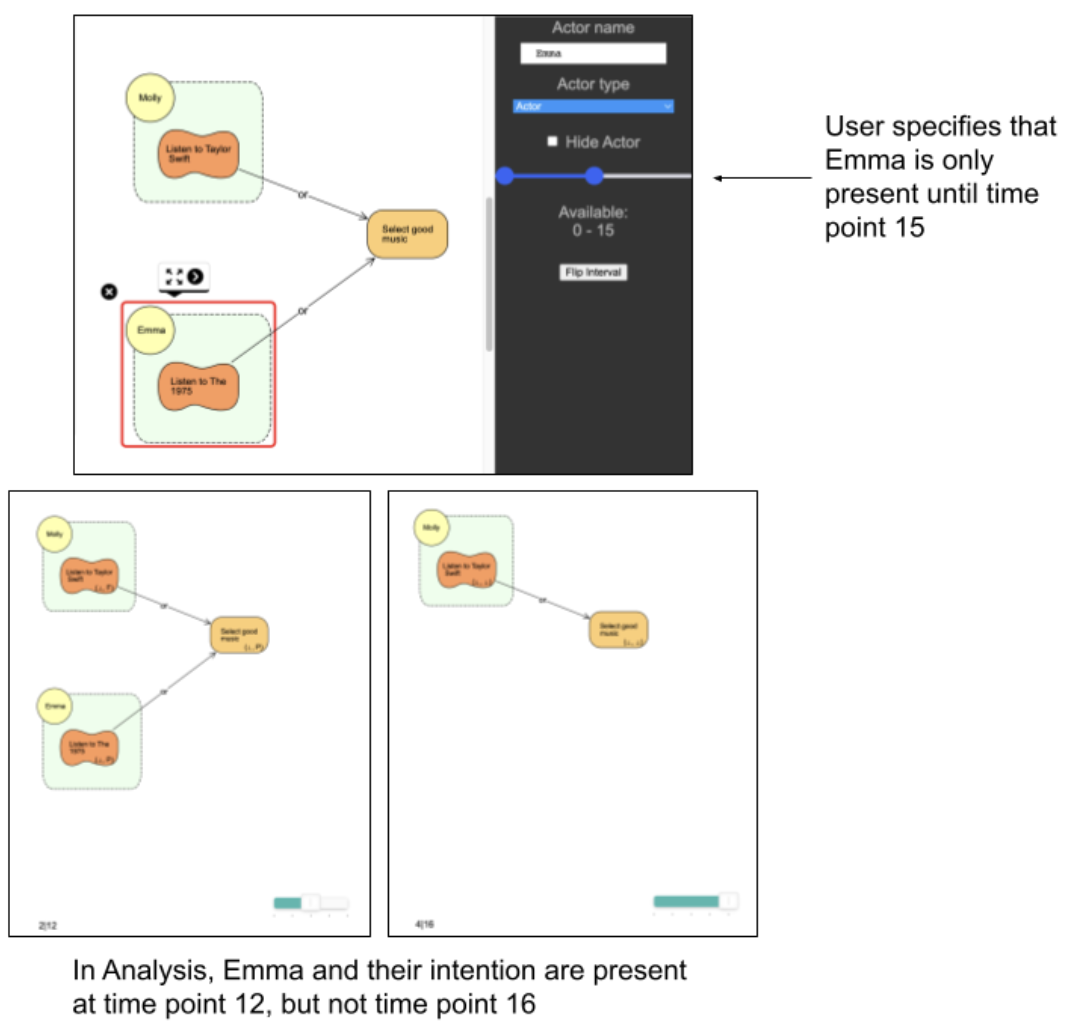
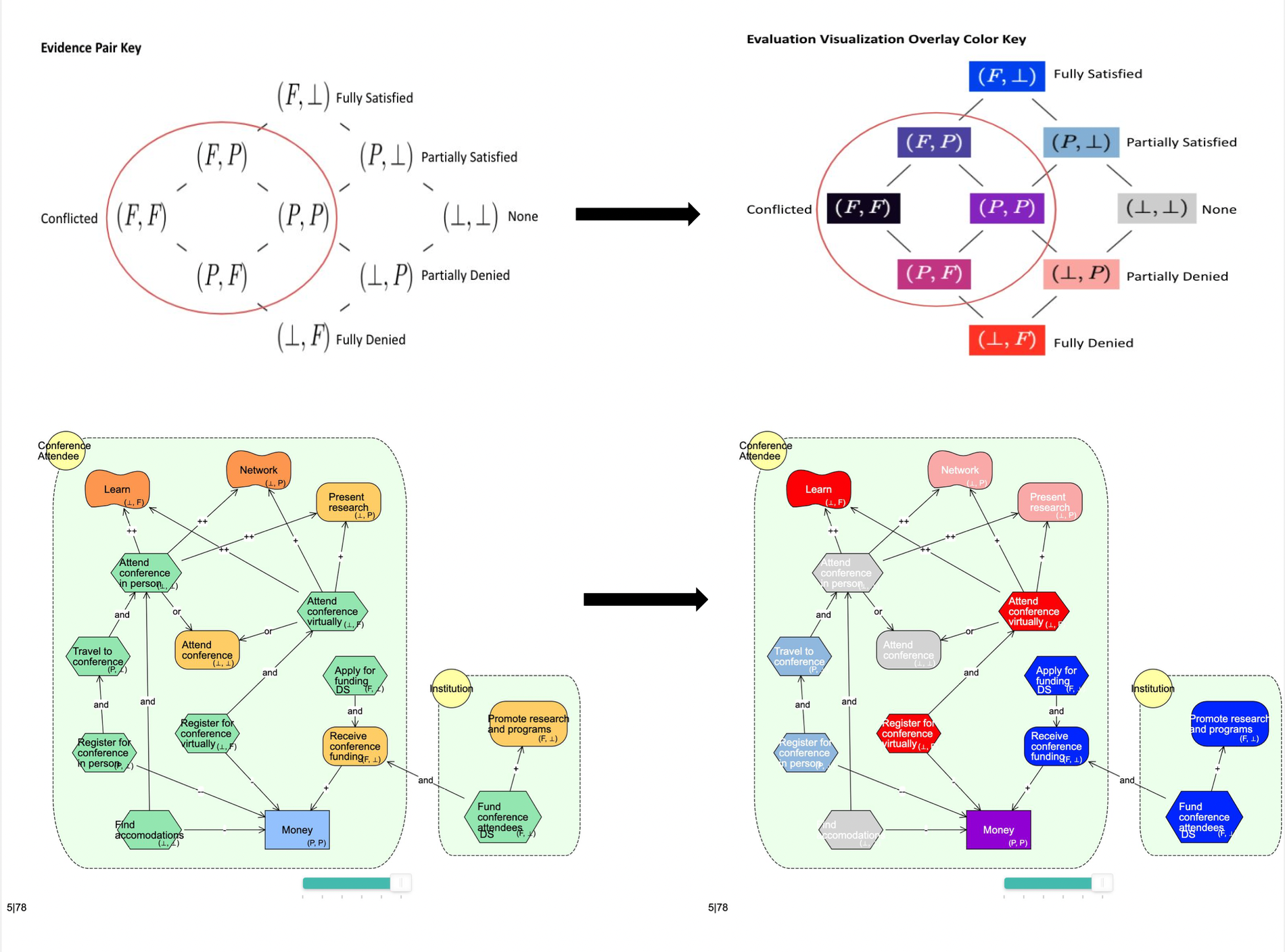
BloomingLeaf is a browser-based goal modeling tool that allows users, primarily stakeholders, to model complex goals composed of numerous actors and intentions, and visualize possible satisfaction outcomes over time. Actors represent individual stakeholders or parties, and intentions represent goals, soft goals, resources, and tasks. BloomingLeaf strives to make goal modeling simpler by providing the user building blocks and a user friendly interface. Such building blocks include draggable intentions that can be connected with varying links. BloomingLeaf differs from other goal modeling tools in its ability to project goals and their satisfaction levels over time, providing the user with a layer of automated analysis.
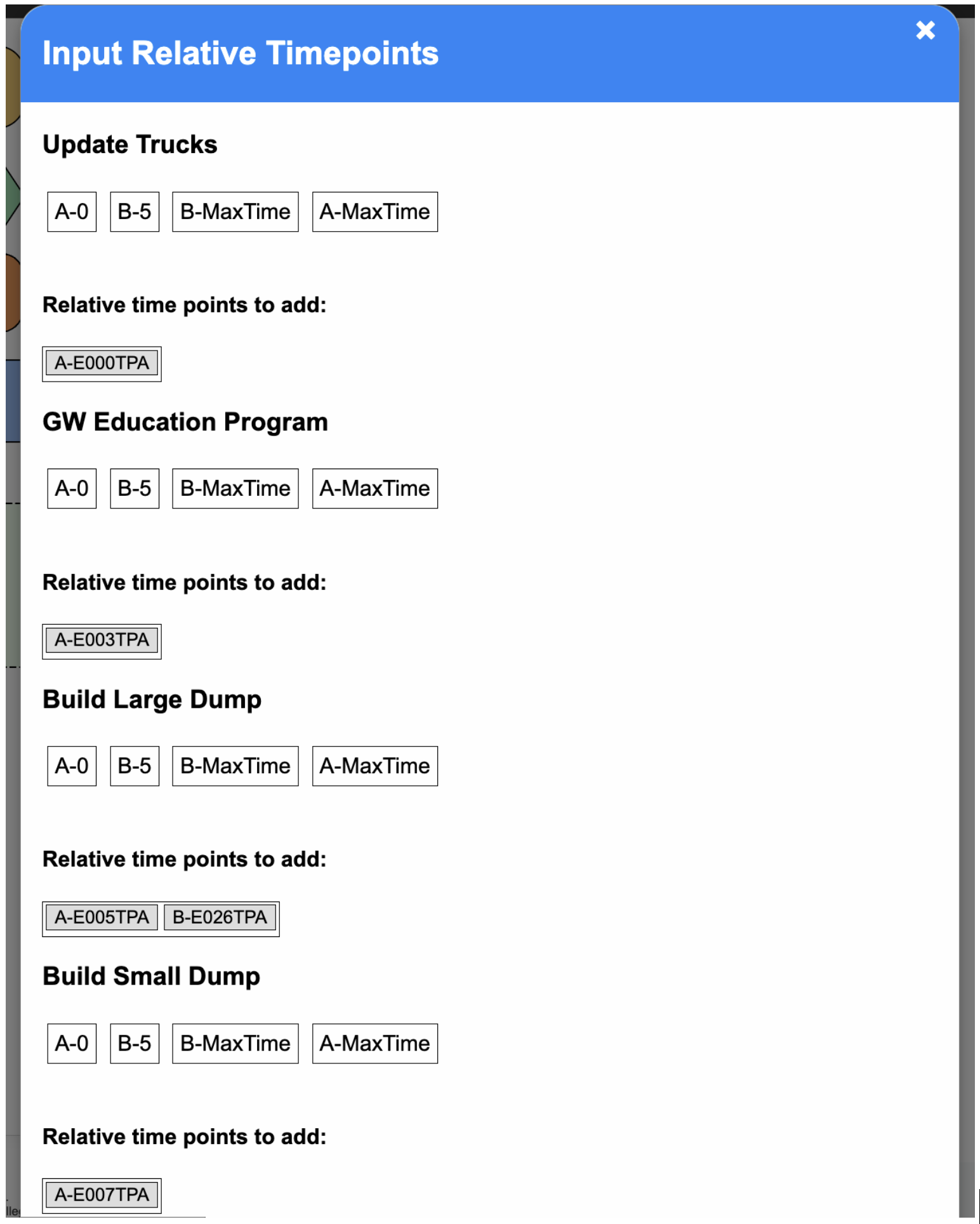
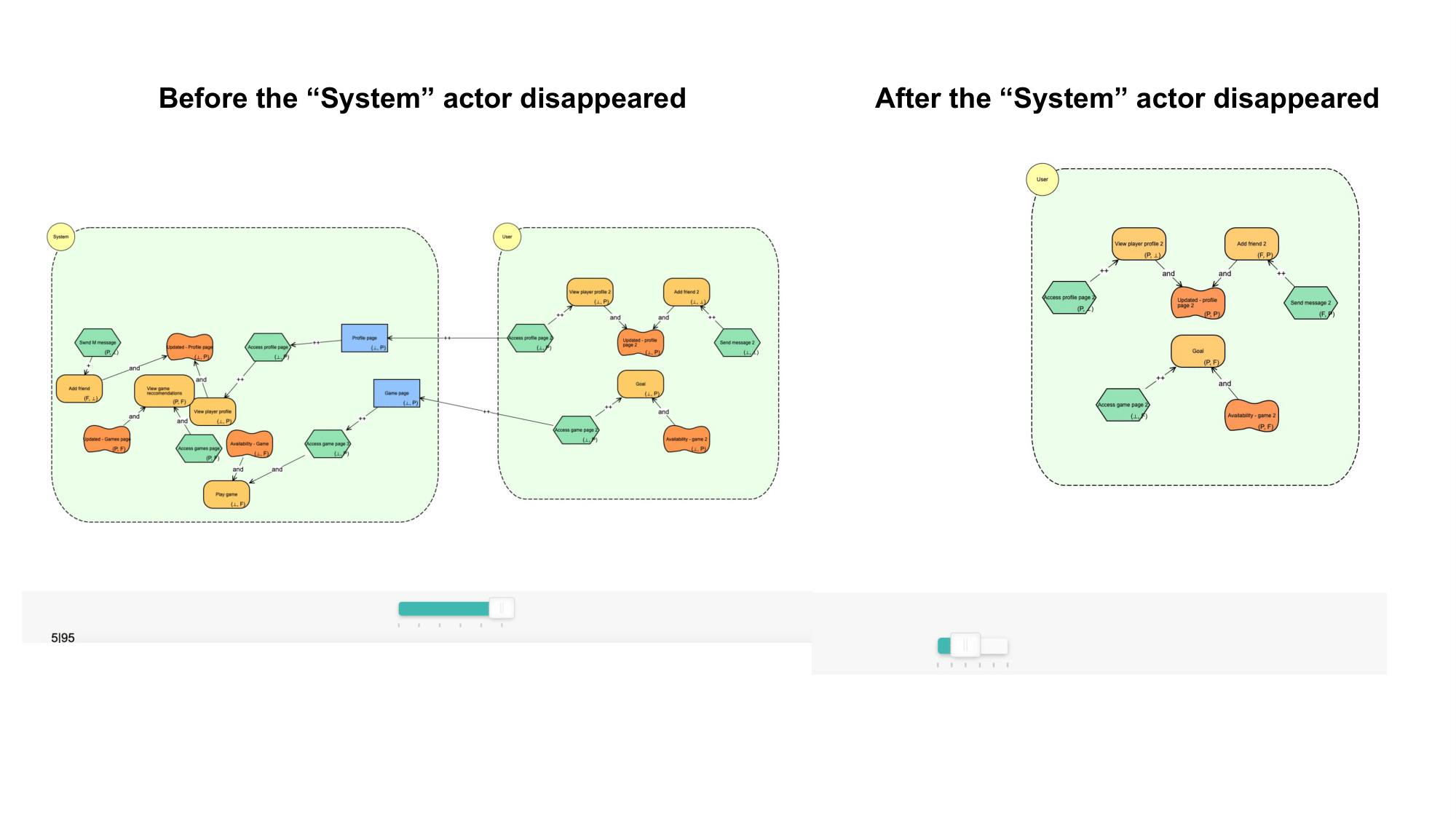
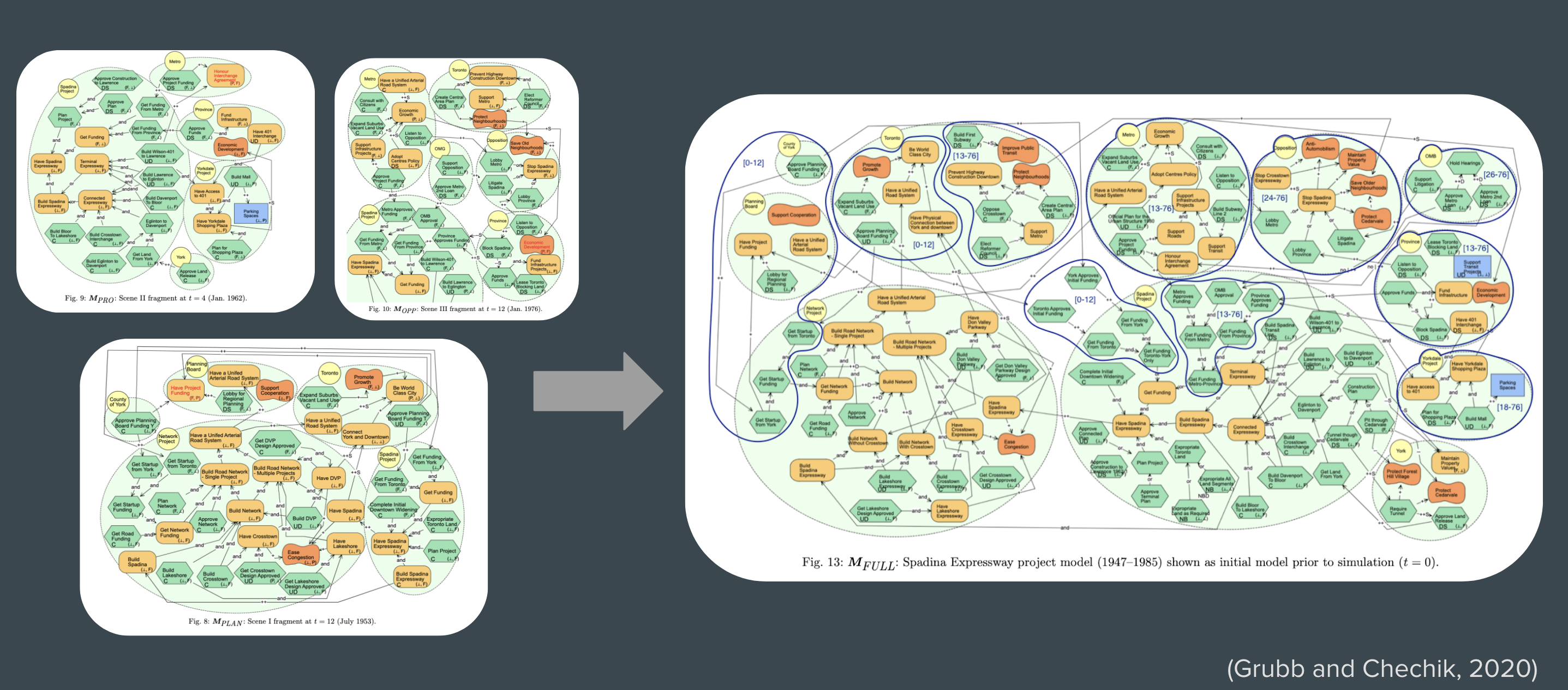
BloomingLeaf gives users the ability to merge two goal models automatically. Previous work in BloomingLeaf implemented an algorithm to merge models and an initial merge option in the user interface. When models have overlapping timelines, user input may be required to complete the merging of models, but the previous version of the merge interface was unequipped to handle this, leading to merge issues.
We addressed this issue by revamping the merge interface, and ensuring that models could merge successfully. In the frontend, we implemented a popup to collect necessary user input on certain goal models. This popup includes draggable elements that allow the user to efficiently order and visualize the timeline of the merged model, and set time points to occur simultaneously (if they so choose). Within this user interface, we implemented multiple validation checks to retain the integrity of the original timelines. We then ensured that the correct information was being sent to and received from the backend.
Finally, we adjusted the merge algorithm to be able to handle simultaneous time points, as well as repeating time points which are the result of the repeat feature that can be used when creating models.
In future work, we will aim to account for all edge cases in order to finalize the merge interface and to guarantee that it works end to end for all models.